들어가며
이전 포스팅에서 go 키워드 하나로 서버를 동시성 서버로 바꿨다. 여러 클라이언트가 동시에 접속해서 PING을 보내면 모두 PONG을 정상적으로 받는다. 다수의 클라이언트가 동시에 연결하는 문제는 해결되었다.
하지만 PING은 저장소에 접근하지 않고 서버에서 특정 응답만 한다. 클라이언트들이 서버에 연결하는 순간 서로에게 공유되는 자원인 map 저장소에 동시에 SET과 GET을 수행하는 순간 현재 구조에서는 경쟁 상태가 발생한다.
이번 포스팅에서는 이 문제의 본질인 Race Condition을 이론적으로 파고들고, 세마포어부터 뮤텍스까지 동기화 기법의 계보를 살펴본 뒤 RWMutex로 저장소를 보호하는 과정을 알아보자.
Race Condition
Race Condition은 두 개 이상의 실행 흐름이 공유 자원에 동시에 접근하면서 그 중 하나 이상이 쓰기작업인 경우 발생하는 현상이다. 핵심은 비결정적 이라는 점이다. 실행할 때마다 고루틴의 스케줄링 순서가 달라지기 때문에 어떤 때는 정상 동작하고 어떤 때는 데이터가 깨진다.
다음 예시를 보며 자세히 살펴보자.
두 개의 스레드가 초기값이 0인 동일한 정수 변수의 값을 1씩 증가시킨다고 가정해보자.
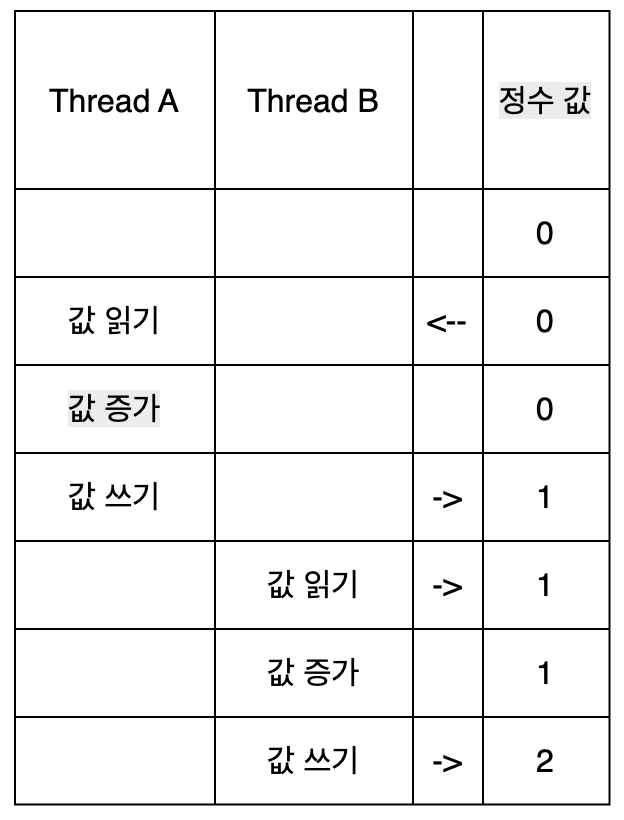
이 상황에서는 문제가 없다. Thread A가 작업하는 도중 Thread B가 같은 정수에 개입 하지않고 Thread A의 작업이 끝나고난 후 Thread B가 작업을 시작하기 때문이다. 하지만 두 스레드가 락이나 동기화 없이 동시에 실행 될 경우 연산결과가 잘못 될 수 있다. 아래의 이미지가 바로 그 예시의 과정이다.
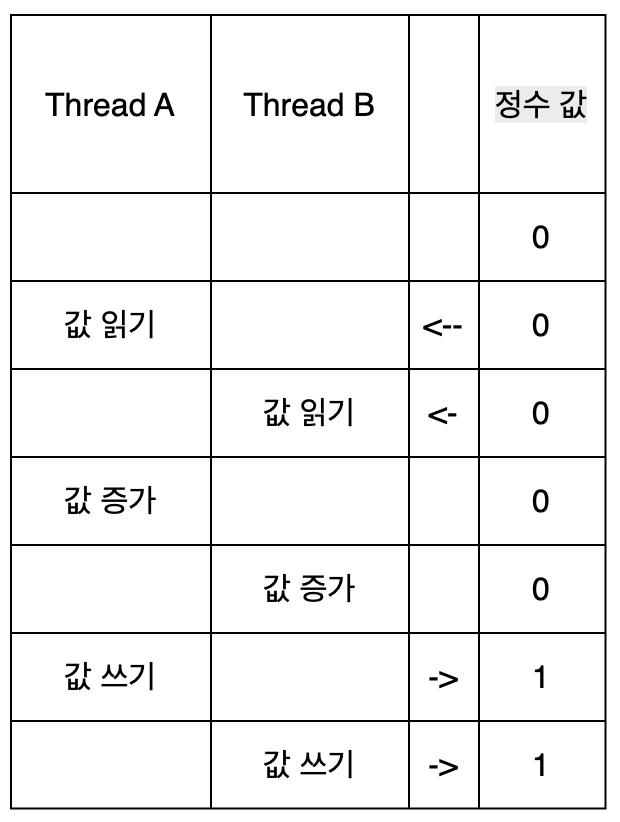
이 경우 최종 값은 예상 결과인 2가 아닌 1이 된다. 증가 연산이 상호 배타적이지 않기 때문에 발생했다. 상호 배타적 연산이란 메모리 위치와 같은 특정 리소스에 접근하는 동안 중단될 수 없는 연산을 말한다.
Data Race vs Race Condition
이 두 개념은 자주 혼용되지만 엄밀히 다르다.
Data Race는 두 고루틴이 같은 메모리 위치에 동시에 접근하면서 하나 이상이 쓰기이고, 둘 사이에 동기화가 없는 저수준 현상이다. 정의 자체가 메모리 접근 패턴에 관한 것이라 프로그램의 의미를 몰라도 자동으로 감지할 수 있다. go의 go test -race가 감지하는 것이 바로 이것이다.
Race Condition은 실행 순서에 따라 프로그램의 논리적 결과가 달라지는 상위 개념이다. 애플리케이션의 의도를 알아야만 판별할 수 있기 때문에 자동 감지가 어렵다.
이 둘의 관계를 정리하면 다음과 같다.
- Data race 없이 race condition이 있을 수 있다
- Data race가 있어도 race condition은 없을 수 있다
- 둘이 동시에 존재할 수도 있다
- 둘 다 없을 수도 있다
Data race 없이 race condition이 존재하는 구체적인 예시를 보겠다.
// data race는 없지만 race condition이 있는 예시
mu.Lock()
count := store.Get("x")
mu.Unlock()
count = count + 1
mu.Lock()
store.Set("x", count)
mu.Unlock()
각 Get과 Set은 뮤텍스로 보호되어 있으므로 data race는 발생하지 않는다. 하지만 Get과 Set 사이에 다른 고루틴이 같은 키를 수정할 수 있기 때문에 증가분이 소실되는 race condition은 여전히 존재한다. 이 경우 Get부터 Set까지를 하나의 원자적 연산으로 묶어야 한다.
mu.Lock()
count := store.Get("x")
count = count + 1
store.Set("x", count)
mu.Unlock()
현재 Store에서는 Set과 Get이 각각 독립적인 연산이고, 하나의 요청 안에서 read-modify-write 패턴을 사용하지 않으므로 data race를 막는 것만으로 충분하다. 하지만 나중에 INCR 같은 명령어를 구현하게 되면 이 구분이 중요해진다.
현재 서버의 문제
5편에서 서버를 동시성 구조로 바꾸면서 모든 클라이언트 고루틴이 같은 Store 인스턴스를 공유하게 되었다.
func New(addr string) *Server {
return &Server{
addr: addr,
store: storage.New(), // 하나의 Store를 모든 고루틴이 공유
}
}
클라이언트 A가 SET을 하는 동안 클라이언트 B가 GET을 하면 다음과 같은 상황이 벌어질 수 있다.
고루틴 A: s.store.Set("x", "1") // map에 쓰기
고루틴 B: s.store.Get("x") // map에서 읽기
해시테이블 기반의 map에서 쓰기 연산 중에는 버킷의 재배치가 일어날 수 있고 이 중간에 다른 고루틴이 읽기를 시도하면 반쯤 업데이트된 상태를 읽게 된다. go 런타임은 이런 동시 접근을 감지하면 fatal error: concurrent map read and map write 메시지와 함께 프로그램을 종료시킨다. 단순한 데이터 불일치가 아니라 프로세스 크래시 수준의 오류다.
임계 구역
공유 자원에 접근하는 코드 영역을 임계 구역(Critical Section) 이라 한다. 동시에 두 개 이상의 고루틴이 임계 구역에 진입하면 레이스 컨디션이 발생한다.
현재 store에서 임계 구역은 s.data에 접근하는 모든 코드이다.
func (s *Store) Set(key, value string) {
s.data[key] = value // 임계 구역 (쓰기)
}
func (s *Store) Get(key string) (string, bool) {
value, exist := s.data[key] // 임계 구역 (읽기)
return value, exist
}
임계 구역 문제의 해법은 다음 세 가지 조건을 모두 만족해야 한다.
상호 배제(Mutual Exclusion) — 한 번에 하나의 실행 흐름만 임계 구역에 진입할 수 있다
진행(Progress) — 임계 구역에 아무도 없으면, 진입하려는 실행 흐름이 무한히 대기해서는 안 된다. 임계 구역에 들어가고 싶은 프로세스들만 진입 결정에 참여하며, 그 결정은 무한히 미뤄질 수 없다
한정 대기(Bounded Waiting) — 한 프로세스가 임계 구역 진입을 요청한 후, 다른 프로세스가 먼저 진입하는 횟수에 상한이 있어야 한다. 요청을 했으면 언젠가는 반드시 들어갈 수 있다는 보장이 필요하다
이 세 조건을 만족하는 대표적인 동기화 도구가 세마포어와 뮤텍스다.
세마포어
세마포어는 다익스트라가 제안한 동기화 기법이다. 다익스트라는 철도 신호기에서 착안해 이 개념을 만들었다. 단선 철로에 열차가 하나만 지나갈 수 있도록 신호기가 통제하는 것처럼 공유 자원에 대한 접근을 카운터로 통제하는 것이다.
세마포어는 내부에 정수 카운터를 가지고 있으며, 두 가지 원자적 연산으로 동작한다.
- P 연산 (wait/acquire) — 카운터를 1 감소시킨다. 카운터가 0이면 양수가 될 때까지 블로킹된다
- V 연산 (signal/release) — 카운터를 1 증가시킨다. 대기 중인 실행 흐름이 있으면 깨운다
카운팅 세마포어와 이진 세마포어
카운터의 초기값에 따라 성격이 달라진다.
카운팅 세마포어는 카운터를 N으로 초기화한다. N개의 실행 흐름이 동시에 자원에 접근할 수 있다. 데이터베이스 커넥션 풀이 대표적인 예시이다. 커넥션이 10개라면 세마포어를 10으로 초기화하고 커넥션을 가져갈 때 P, 반납할 때 V를 호출한다. 11번째 요청은 누군가 커넥션을 반납할 때까지 블로킹된다.
이진 세마포어는 카운터를 1로 초기화한다. 한 번에 하나의 실행 흐름만 진입할 수 있으므로 동작만 놓고 보면 뮤텍스와 비슷하다.
세마포어와 뮤텍스의 차이
이진 세마포어와 뮤텍스가 동일하다고 설명하는 자료가 많지만, 엄밀히는 다르다. 핵심 차이는 소유권 이다.
- 뮤텍스는 잠금을 획득한 고루틴만 해제할 수 있다. 소유권이 있다
- 세마포어는 누가 P를 호출했든 아무나 V를 호출할 수 있다. 소유권이 없다
이 차이가 실질적으로 중요한 이유는 우선순위 역전(Priority Inversion) 문제 때문이다. 뮤텍스는 소유권이 있기 때문에 “누가 잠금을 가지고 있는지” 알 수 있고, 이를 활용한 우선순위 상속(Priority Inheritance) 메커니즘으로 우선순위 역전을 방지할 수 있다. 세마포어는 소유자가 없으므로 이런 메커니즘을 적용하기 어렵고 개발자의 실수로 데드락이나 상호 배제 위반이 발생하기 더 쉽다.
이런 이유로 뮤텍스는 임계 구역 보호에 특화되어 있고 세마포어는 자원 접근 수 제한이나 실행 흐름 간 신호에 더 적합하다.
go의 표준 라이브러리에는 세마포어가 없다. sync.Mutex와 채널을 조합하면 세마포어의 역할을 대체할 수 있기 때문이다. go는 “공유 메모리로 통신하지 말고, 통신으로 메모리를 공유하라” 는 철학을 가지고 있어서 채널 기반 동기화를 더 권장한다. 다만 현재 내가 구현한 store 저장소처럼 단순한 공유 자원 보호에는 뮤텍스가 가장 직관적이고 효율적인 선택이다.
Mutex
뮤텍스(Mutex)는 Mutual Exclusion의 약자로 한 번에 하나의 고루틴만 임계 구역에 진입할 수 있게 하는 잠금 장치다.

동작 방식은 단순하다.
- 고루틴 A가
Lock()을 호출하면 잠금을 획득한다 - 고루틴 B가
Lock()을 호출하면, A가Unlock()할 때까지 블로킹된다 - A가
Unlock()을 호출하면 B가 잠금을 획득하고 진입한다
Spinlock vs Mutex
잠금을 획득하지 못했을 때 대기하는 방식에는 두 가지가 있다.
Spinlock 은 잠금을 획득할 때까지 루프를 돌며 계속 확인한다. CPU를 점유한 채 대기하므로 “바쁜 대기(Busy Waiting)“라고 한다. 임계 구역이 극히 짧은 경우에는 sleep/wakeup의 컨텍스트 스위칭 오버헤드보다 스핀이 더 효율적이다. 반대로 임계 구역이 길면 CPU 시간만 낭비하게 된다.
Mutex(슬리핑 락) 는 잠금을 획득하지 못하면 고루틴을 대기 상태로 전환하고 CPU를 양보한다. 잠금이 해제되면 대기 중인 고루틴을 깨운다. 컨텍스트 스위칭 비용이 발생하지만 CPU를 낭비하지 않는다.
Go의 sync.Mutex는 이 둘을 혼합한 하이브리드 방식이다. 구현 내부를 보면 잠금을 획득하지 못한 고루틴은 먼저 최대 4번 스핀을 시도한다. 각 스핀은 CPU 명령어 수준에서 30사이클씩 루프를 돌며(총 120사이클), 이 짧은 시간 안에 잠금이 풀리면 컨텍스트 스위칭 없이 바로 획득한다. 그래도 못 얻으면 대기 큐에 들어가 슬립한다. 멀티코어 환경에서만 스핀이 활성화되며 싱글코어에서는 스핀할 의미가 없으므로 바로 슬립한다.
Go Mutex의 Normal 모드와 Starvation 모드
Go 1.9부터 sync.Mutex에는 Starvation 모드가 도입되었다.
Normal 모드에서는 대기 중인 고루틴이 깨어나면 새로 도착한 고루틴들과 잠금을 놓고 경쟁한다. 새로 도착한 고루틴은 이미 CPU 위에서 돌고 있으므로 대기 큐에서 깨어난 고루틴보다 유리하다. 대기 큐의 고루틴이 경쟁에서 지면 큐의 맨 앞으로 돌아가지만 계속 지면 영원히 잠금을 획득하지 못할 수 있다.
Starvation 모드는 대기 큐의 고루틴이 1밀리초 이상 잠금을 획득하지 못하면 활성화된다. 이 모드에서는 경쟁이 사라진다. 잠금을 해제한 고루틴이 대기 큐의 맨 앞 고루틴에게 직접 잠금을 넘겨주는(handoff) 방식으로 바뀐다. 대기 큐의 마지막 고루틴이거나 대기 시간이 1ms 미만이면 다시 normal 모드로 돌아간다.
이 설계는 임계 구역에서 설명한 한정 대기 조건을 보장하기 위한 것이다. normal 모드만으로는 특정 고루틴이 영원히 잠금을 얻지 못하는 기아가 발생할 수 있다.
Mutex의 한계
뮤텍스는 race condition 문제를 해결하지만, 모든 접근을 직렬화한다는 한계가 있다. 읽기끼리도 서로 블로킹된다.
데이터베이스 워크로드를 생각해보면 대부분의 요청은 GET(읽기)이고 SET(쓰기)은 상대적으로 적다. 읽기는 데이터를 변경하지 않으므로 여러 고루틴이 동시에 읽어도 안전하다. 그런데도 읽기마다 Lock()으로 잠그면 불필요한 병목이 생긴다.
RWMutex
sync.RWMutex는 읽기-쓰기 잠금(Readers-Writer Lock)의 Go 구현이다. 뮤텍스가 모든 접근을 직렬화하는 것과 달리 읽기끼리는 동시에 통과시킨다.
| 연산 | 메서드 | 동시 접근 |
|---|---|---|
| 읽기 | RLock() / RUnlock() | 여러 고루틴이 동시에 읽기 가능 |
| 쓰기 | Lock() / Unlock() | 단 하나의 고루틴만 쓰기 가능. 읽기도 모두 차단 |
규칙을 정리하면 다음과 같다.
- 읽기-읽기 → 동시 통과 (블로킹 없음)
- 읽기-쓰기 → 상호 배타적 (한쪽이 대기)
- 쓰기-쓰기 → 상호 배타적 (한쪽이 대기)
쓰기 기아(Writer Starvation)와 공정성 정책
읽기-쓰기 잠금에는 세 가지 공정성 정책이 있다.
읽기 우선(Read-Preferring) - 읽기 요청이 있으면 즉시 통과시킨다. 동시성이 최대화되지만 읽기 요청이 끊임없이 들어오면 쓰기는 영원히 잠금을 획득하지 못한다. 이것이 쓰기 기아(Writer Starvation) 이다.
쓰기 우선(Write-Preferring) - 쓰기 요청이 대기 중이면 새로운 읽기 요청을 블로킹한다. 쓰기 기아를 방지하지만, 쓰기가 자주 발생하면 읽기의 동시성이 떨어진다.
공정(Fair) - 요청 순서(FIFO)대로 처리한다. 읽기와 쓰기 모두 기아가 없지만 구현이 복잡하다.
sync.RWMutex는 쓰기 우선 정책을 사용한다. Go 공식 문서에도 명시되어 있다. 쓰기 잠금이 대기 중이면 새로운 읽기 잠금 요청은 블로킹된다. 이미 잠금을 획득한 읽기가 모두 끝나면 쓰기가 먼저 진입하고, 쓰기가 끝난 뒤에 대기 중이던 읽기들이 통과한다.
잠금 세분화
현재 store는 하나의 RWMutex로 전체 map을 보호한다. 가장 단순한 방식이고 지금 단계에서는 충분하다.
하지만 데이터가 수백만 건이고 동시 요청이 수천 개인 상황을 생각해보면, "user:1"에 대한 SET이 "user:9999"에 대한 GET까지 블로킹하는 것은 불필요하다. 서로 다른 키에 대한 연산은 충돌할 이유가 없기 때문이다.
이런 경우 키를 여러 그룹으로 나누고 그룹별로 별도의 뮤텍스를 거는 방식을 쓸 수 있다. 이것을 잠금 세분화(Lock Granularity) 또는 샤딩(Sharding) 이라 한다. Java의 ConcurrentHashMap이 이 방식을 사용한다. 세분화할수록 동시성은 높아지지만, 잠금 관리의 복잡도가 올라가고 메모리 사용량도 증가하는 트레이드오프가 있다.
데드락
뮤텍스를 사용할 때 주의해야 하는 것이 데드락(교착상태)** 이다. 두 개 이상의 고루틴이 서로가 가진 잠금을 기다리며 영원히 멈추는 상태다.
고루틴 A: Lock(뮤텍스1) 획득 → Lock(뮤텍스2) 대기...
고루틴 B: Lock(뮤텍스2) 획득 → Lock(뮤텍스1) 대기...
→ 둘 다 영원히 대기
고루틴 A는 뮤텍스2를 기다리고, 뮤텍스2를 가진 고루틴 B는 뮤텍스1을 기다린다. 어느 쪽도 양보하지 않으므로 프로그램이 멈춘다.
코프만 조건 (교착상태의 4가지 조건)
코프만은 데드락이 발생하려면 다음 네 가지 조건이 동시에 성립해야 한다고 정리했다. 흔히 아는 교착 상태의 4가지 조건이다.
상호 배제(Mutual Exclusion) — 자원을 동시에 공유할 수 없다. 뮤텍스 자체가 이 조건에 해당한다
점유 대기(Hold and Wait) — 자원을 하나 이상 점유한 채 다른 자원을 기다린다. 위 예시에서 고루틴 A는 뮤텍스1을 점유한 채 뮤텍스2를 기다린다
비선점(No Preemption) — 이미 획득한 자원을 강제로 빼앗을 수 없다. 고루틴 A가 들고 있는 뮤텍스1을 외부에서 강제로 해제할 방법이 없다
순환 대기(Circular Wait) — 고루틴들이 원형으로 서로의 자원을 기다린다. A→B→A로 순환이 형성된다
이 네 조건 중 하나라도 깨면 데드락은 발생하지 않는다. 실무에서 가장 많이 사용하는 전략은 순환 대기를 깨는 것이다. 모든 뮤텍스에 번호를 매기고, 항상 번호가 작은 것부터 획득하면 순환이 만들어질 수 없다.
식사하는 철학자 문제
데드락을 설명하는 가장 유명한 예제가 다익스트라가 1965년에 제안한 식사하는 철학자 문제 이다.

다섯 명의 철학자가 원형 테이블에 앉아 있고, 각 철학자 사이에 포크가 하나씩 놓여 있다. 식사를 하려면 양쪽 포크를 모두 들어야 한다. 철학자는 “생각하기"와 “먹기"만 번갈아 할 수 있다. 모든 철학자가 동시에 왼쪽 포크를 집으면, 각자 오른쪽 포크를 기다리며 아무도 식사를 할 수 없게 된다. 코프만 조건을 대입해보면 상호 배제(포크는 공유 불가), 점유 대기(왼쪽 포크를 든 채 오른쪽 대기), 비선점(남의 포크를 뺏을 수 없음), 순환 대기(원형 테이블)가 모두 성립한 것이다.
다익스트라의 해법 중 하나는 세마포어를 사용하는 것이다. 각 철학자에 대해 세마포어를 두고, 양쪽 포크가 모두 사용 가능할 때만 원자적으로 두 포크를 함께 집도록 한다. 더 단순한 해결책은 포크에 번호를 매기고, 항상 번호가 작은 포크부터 집도록 하는 것이다. 이렇게 하면 순환 대기가 깨져서 데드락이 불가능해진다.
현재의 store는 뮤텍스가 하나뿐이므로 데드락이 발생할 수 없다. 점유 대기와 순환 대기 조건이 성립할 수 없기 때문이다. 시스템이 커져서 여러 뮤텍스를 사용하게 되면 이 개념이 중요해지겠지만 말이다.
Go Race Detector
Go는 go test -race 플래그로 Race Detector를 제공한다. 컴파일 시점에 모든 메모리 접근을 추적하는 코드를 삽입하고, 실행 중에 두 고루틴이 같은 메모리에 동시 접근하면서 하나 이상이 쓰기인 경우를 감지해 리포트를 출력한다.
엄밀히 말하면 Race Detector가 감지하는 것은 Race Condition이 아니라 Data Race다. 앞서 설명한 것처럼, 모든 메모리 접근이 뮤텍스로 보호되어 있어도 논리적인 race condition은 남을 수 있다. Race Detector는 동기화 없는 메모리 접근만 감지한다. data race의 정의 자체가 프로그램 의미와 무관하게 메모리 접근 패턴만으로 판별 가능하기 때문에 자동 감지가 가능한 것이다.
또 하나 주의할 점은 Race Detector가 실제로 발생한 data race만 감지한다는 것이다. 코드에 race 가능성이 있더라도 테스트 실행 중에 고루틴 간 타이밍이 맞지 않으면 감지하지 못할 수 있다. 그래서 동시성 테스트에서는 충분히 많은 고루틴을 띄워서 race가 발생할 확률을 높이는 것이 중요하다.
코드 구현
store.go
package storage
import "sync"
type Store struct {
data map[string]string
mu sync.RWMutex
}
func New() *Store {
return &Store{data: make(map[string]string)}
}
func (s *Store) Set(key, value string) {
s.mu.Lock()
s.data[key] = value
s.mu.Unlock()
}
func (s *Store) Get(key string) (string, bool) {
// 서로다른 고루틴 간의 읽기 작업에서는 블로킹 없이 동시에 통과
// A 고루틴이 쓰기 작업 도중, B 고루틴이 데이터를 읽고 있다면 데이터 불일치 현상이 생길 수 있기때문에
// RLock(읽기)이 걸려있으면 Lock(쓰기)은 대기, Lock이 걸려있으면 RLock은 대기
s.mu.RLock()
value, exist := s.data[key]
s.mu.RUnlock()
return value, exist
}
store_test.go (동시성 테스트)
func TestConcurrentSetGet(t *testing.T) {
// given
store := New()
var wg sync.WaitGroup
// when: 여러 고루틴이 동시에 SET/GET 수행
for i := 0; i < 100; i++ {
wg.Add(2)
go func(n int) {
defer wg.Done()
key := fmt.Sprintf("key-%d", n)
store.Set(key, "value")
}(i)
go func(n int) {
defer wg.Done()
key := fmt.Sprintf("key-%d", n)
store.Get(key)
}(i)
}
wg.Wait()
// then: -race 플래그로 실행 시 race가 감지되지 않아야 함
}
func TestConcurrentWrite(t *testing.T) {
// given
store := New()
var wg sync.WaitGroup
// when: 100개의 고루틴이 같은 키에 동시 쓰기
for i := 0; i < 100; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
store.Set("counter", fmt.Sprintf("%d", n))
}(i)
}
wg.Wait()
// then: 값이 존재해야 함 (어떤 값이든)
value, exist := store.Get("counter")
if !exist {
t.Fatal("counter 키가 존재하지 않음")
}
// value는 0~99 중 하나 (마지막에 쓴 고루틴의 값)
t.Logf("최종 값: %s", value)
}
server_test.go (통합 테스트)
func TestConcurrentSetGet(t *testing.T) {
// given
server := New(":6379")
go server.Start()
time.Sleep(time.Second)
var wg sync.WaitGroup
// when: 여러 클라이언트가 동시에 SET/GET
for i := 0; i < 10; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
conn, _ := net.Dial("tcp", "localhost:6379")
defer conn.Close()
key := fmt.Sprintf("key%d", id)
value := fmt.Sprintf("value%d", id)
keyLen := len(key)
valueLen := len(value)
// SET
setCmd := fmt.Sprintf("*3\r\n$3\r\nSET\r\n$%d\r\n%s\r\n$%d\r\n%s\r\n", keyLen, key, valueLen, value)
conn.Write([]byte(setCmd))
reader := bufio.NewReader(conn)
setResponse, _ := reader.ReadString('\n')
if setResponse != "+OK\r\n" {
t.Errorf("클라이언트 %d SET 실패: %s", id, setResponse)
return
}
// GET
getCmd := fmt.Sprintf("*2\r\n$3\r\nGET\r\n$%d\r\n%s\r\n", keyLen, key)
conn.Write([]byte(getCmd))
getResponse1, _ := reader.ReadString('\n')
getResponse2, _ := reader.ReadString('\n')
getResp := getResponse1 + getResponse2
expected := fmt.Sprintf("$%d\r\n%s\r\n", valueLen, value)
if getResp != expected {
t.Errorf("클라이언트 %d GET 실패: %s, expected: %s", id, getResp, expected)
}
}(i)
}
wg.Wait()
// then: -race로 실행 시 race가 감지되지 않아야 함
}
라인별 Deep Dive
sync.RWMutex 필드 추가
type Store struct {
data map[string]string
mu sync.RWMutex
}
mu는 값 타입이다. 포인터가 아니기 때문에 Store 구조체에 그대로 내장하면 된다. sync.RWMutex의 제로 값이 바로 잠금이 풀린 상태이므로, New()에서 별도로 초기화할 필요가 없다. make(map[string]string)처럼 명시적으로 초기화해야 하는 map과는 다르다.
Set - 쓰기 잠금
func (s *Store) Set(key, value string) {
s.mu.Lock()
s.data[key] = value
s.mu.Unlock()
}
Lock()은 배타적 잠금이다. 이 잠금이 걸려 있는 동안 다른 고루틴의 Lock()과 RLock() 모두 블로킹된다. RWMutex 규칙에 따라 쓰기-쓰기, 쓰기-읽기 모두 상호 배타적으로 동작한다.
s.data[key] = value가 임계 구역이다. map의 쓰기 연산은 내부적으로 해시 계산, 버킷 탐색, 값 삽입이 여러 단계로 일어나므로, 이 과정 중에 다른 접근이 끼어들면 map의 내부 상태가 깨질 수 있다. Lock()과 Unlock()으로 이 구간을 보호한다.
Get - 읽기 잠금
func (s *Store) Get(key string) (string, bool) {
s.mu.RLock()
value, exist := s.data[key]
s.mu.RUnlock()
return value, exist
}
RLock()은 읽기 잠금이다. 여러 고루틴이 동시에 RLock()을 획득할 수 있으므로 GET 요청이 몰려도 서로를 블로킹하지 않는다. 다만 Lock()(쓰기)이 걸려 있으면 RLock()도 대기한다. 쓰기 도중에 반쯤 업데이트된 데이터를 읽는 것을 막기 위해서다.
만약 일반 Mutex를 사용했다면 GET 10개가 동시에 들어와도 하나씩 차례로 처리해야 한다. RWMutex를 사용하면 10개 GET이 동시에 통과하고, SET이 들어올 때만 잠깐 대기한다. 읽기가 압도적으로 많은 데이터베이스 워크로드에서 이 차이는 크다.
TestConcurrentSetGet (store)
for i := 0; i < 100; i++ {
wg.Add(2)
go func(n int) {
defer wg.Done()
key := fmt.Sprintf("key-%d", n)
store.Set(key, "value")
}(i)
go func(n int) {
defer wg.Done()
key := fmt.Sprintf("key-%d", n)
store.Get(key)
}(i)
}
루프 한 번에 SET 고루틴과 GET 고루틴을 동시에 생성한다. wg.Add(2)로 두 개를 한꺼번에 등록하는 이유다. 같은 키(key-0, key-1, …)에 대해 읽기와 쓰기가 동시에 일어나도록 설계했다.
테스트는 go test -race로 실행했을 때 Race Detector가 경고를 출력하지 않으면 통과이다.
TestConcurrentWrite (store)
for i := 0; i < 100; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
store.Set("counter", fmt.Sprintf("%d", n))
}(i)
}
100개의 고루틴이 같은 키 "counter"에 동시에 쓰기를 수행한다. TestConcurrentSetGet과의 차이점은 쓰기-쓰기 충돌을 검증한다는 것이다. 100개의 고루틴이 모두 Lock()을 경쟁하므로 뮤텍스의 상호 배제가 제대로 동작하는지 확인할 수 있다.
최종 값은 0~99 중 어떤 값이든 될 수 있다. 어떤 고루틴이 마지막에 실행될지는 스케줄링에 따라 달라지기 때문이다. 중요한 것은 값이 반드시 존재한다는 점과, race가 감지되지 않는다는 점이다.
TestConcurrentSetGet (server 통합)
key := fmt.Sprintf("key%d", id)
value := fmt.Sprintf("value%d", id)
keyLen := len(key)
valueLen := len(value)
서버 통합 테스트는 store 단위 테스트와 달리 TCP 연결을 통해 RESP 프로토콜로 명령어를 보낸다. 실제 클라이언트와 동일한 경로를 거치므로 프로토콜 파싱부터 저장소 접근까지 전체 파이프라인의 동시성을 검증한다.
각 고루틴이 고유한 키(key0, key1, …)를 사용하는 이유는 자신이 SET한 값을 GET으로 다시 읽어서 검증하기 위해서다. 같은 키를 공유하면 다른 고루틴이 덮어쓴 값이 조회될 수 있어 테스트 결과를 예측할 수 없게 된다.
마치며
RWMutex 하나로 동시 접근 문제가 해결되었다. SET에는 Lock/Unlock으로 배타적 쓰기 잠금을, GET에는 RLock/RUnlock으로 공유 읽기 잠금을 적용했다. 읽기끼리는 서로 블로킹하지 않으면서 읽기-쓰기 간에는 상호 배제가 보장된다.
지금까지 TCP 소켓으로 서버를 열고, RESP 프로토콜을 파싱하고, 키-값 저장소를 구현하고, 고루틴으로 동시 처리를 하고, 뮤텍스로 동시 접근을 보호하는 것까지 왔다. 다음 포스팅에서는 List 자료구조를 직접 구현해서 LPUSH, RPUSH, LPOP 등과 같은 명령어를 추가해보겠다.
참고
- https://pkg.go.dev/sync
- https://go.dev/doc/articles/race_detector
- https://go.dev/blog/codelab-share
- https://barrgroup.com/blog/mutexes-and-semaphores-demystified
- https://blog.regehr.org/archives/490
- https://en.wikipedia.org/wiki/Critical_section
- https://en.wikipedia.org/wiki/Semaphore_(programming)
- https://gobyexample.com/channels